W dokumentacji dotyczącej przechowywania danych i tego jak zbudowana jest struktura PostgreSQL, natkniesz się na mniej popularne terminy. Pozwól, że spróbuję wyjaśnić, co oznaczają:
- krotka(row) lub element to synonim dla wiersza,
- relacja(table) to synonim dla tabeli,
- filenode to identyfikator reprezentujący odniesienie do tabeli lub indeksu,
- blok(block) i strona(page) są tym samym i reprezentują segment informacji o rozmiarze 8 kB, przechowywany w pliku tabeli,
- sterta(heap) odnosi się do pliku sterty(heap file). Pliki sterty to listy nieuporządkowanych rekordów o zmiennej wielkości. Choć mają podobną nazwę, pliki sterty różnią się od struktury danych sterty(heap file structure),
- CTID reprezentuje fizyczną lokalizację wersji wiersza w tabeli. CTID to również specjalna kolumna dostępna dla każdej tabeli, ale niewidoczna, chyba że zostanie specjalnie wymieniona. Składa się z numeru strony i identyfikatora elementu,
- OID oznacza Object Identifier (Identyfikator Obiektu),
- klastry bazy danych – nazywamy klastrami bazy danych obszar przechowywania na dysku. Klastr bazy danych to zbiór baz danych zarządzanych przez pojedynczą instancję działającego serwera baz danych – PGDATA,
- VACUUM – bazy danych PostgreSQL wymagają okresowych czynności konserwacyjnych, znanych jako odkurzanie (ang. vacuuming).

Przechowywanie bazy danych
Pliki danych używane przez klaster bazy danych są przechowywane razem w katalogu danych klastra, często nazywanym PGDATA. PGDATA może mieć różne lokalizacje, zależnie od systemu operacyjnego lub instalacji.
Dla każdej bazy danych w klastrze istnieje podkatalog w PGDATA/base, nazwany na podstawie OID bazy danych w tabeli pg_database. Ten podkatalog jest domyślną lokalizacją plików bazy danych.
Możesz użyć następującego zapytania by sprawdzić OID baz:
select oid, datname from pg_database;Przechowywanie tabel
Struktura PostgreSQL przechowuje każdą tabelę w osobnym pliku. Dla zwykłych relacji, pliki te mają nazwy odpowiadające numerowi filenode tabeli lub indeksu. Znajdziesz je w kolumnie relfilenode w pg_class. Tabela ta istnieje w schemacie pg_catalog.
Gdy tabela przekracza 1 GB, jest podzielona na segmenty o rozmiarze gigabajta. Nazwa pliku pierwszego segmentu jest taka sama jak filenode; kolejne segmenty mają nazwy filenode.1, filenode.2 itd. Taki układ unika problemów na platformach, które mają ograniczenia dotyczące rozmiaru pliku.
Filenode tabeli często odpowiada jej OID, ale nie zawsze. Aby znaleźć ścieżkę do filenode tabeli, możesz uruchomić następujące zapytanie:
select pg_relation_filepath('nazwaTabeli');Tabele systemowe
Warto wiedzieć, że istnieje specjalny schemat katalogowy (system catalog schema), który zawiera tabele, z których możesz chcieć pobrać dodatkowe informacje.
Podczas tworzenia bazy danych, oprócz schematów publicznych i użytkowników, każda baza danych zawiera schemat pg_catalog. Zawiera on tabele systemowe oraz wszystkie wbudowane typy danych, funkcje i operatory. Schemat pg_catalog jest zawsze efektywną częścią ścieżki wyszukiwania (search path), więc nie musisz używać prefiksu przy zapytaniach do tabel systemowych. Tabele te przechowują metadane na temat całego PostgreSQL.
Przechowywanie wierszy
Każda tabela jest przechowywana jako tablica stron o stałym rozmiarze (zazwyczaj 8 KB). W tabeli wszystkie strony są logicznie równoważne, więc określony element (wiersz) może być przechowywany na dowolnej stronie.
Strukturą używaną do przechowywania tabeli jest plik sterty (heap file). Pliki sterty to listy nieuporządkowanych rekordów o zmiennej wielkości. Plik sterty jest zbudowany jako zbiór stron (bloków), z których każda zawiera kolekcję elementów. Termin „element” odnosi się do wiersza przechowywanego na stronie.
Struktura strony wygląda następująco:
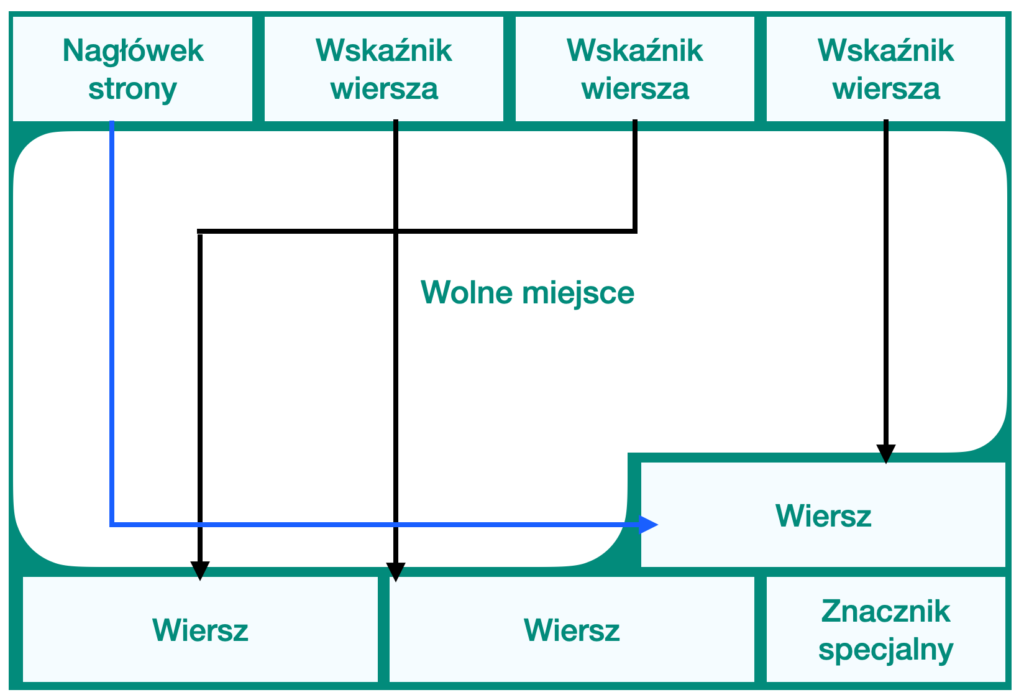
Zawiera ona nagłówki dostarczające informacji o sumie kontrolnej, początku wolnego miejsca, końcu wolnego miejsca itp. Elementy po nagłówkach to identyfikator tablicy składający się z par (offset, długość), wskazujących na rzeczywiste elementy.
Ponieważ identyfikator elementu nigdy nie jest przenoszony, jego indeks można długoterminowo używać do odwoływania się do elementu. Wskaźnik do elementu nazywa się CTID (ItemPointer) i jest tworzony przez PostgreSQL. Składa się on z numeru strony i indeksu identyfikatora elementu.
Same elementy są przechowywane w przestrzeni przydzielonej od końca pustej przestrzeni. Podsumowując, wewnątrz strony wskaźniki do wiersza są przechowywane na początku, a krotki (wiersze) są przechowywane na końcu strony.
Jeżeli chcesz nauczyć się konfigurować PostgreSQL, sprawdź kompleksowy Kurs Praktyczna Administracja PostgreSQL!
Struktura PostgreSQL – ograniczenia
W PostgreSQL, maksymalna liczba kolumn mieści się w zakresie od 250 do 1600, w zależności od typów kolumn. Typy kolumn są istotne, ponieważ w PostgreSQL wiersze mogą mieć maksymalną szerokość wynoszącą 8 kB (jedna strona).
To jednak nie oznacza, że wartość kolumny jest ograniczona do 8 kB. Możliwe jest przechowywanie dużych wartości w kolumnach, ponieważ PostgreSQL posiada mechanizm o nazwie TOAST, który może się tym zająć. Istnieje jednak ograniczenie dotyczące liczby kolumn, które można pomieścić, zależne od szerokości używanych typów danych. Nawet wskaźnik do atrybutu TOAST nadal wymaga pewnej liczby bajtów.
Mechanizm TOAST
TOAST oznacza The Oversized-Attribute Storage Technique.
PostgreSQL używa stałej wielkości strony (zazwyczaj 8 kB) i nie pozwala na rozciąganie wierszy na wiele stron. Dlatego niemożliwe jest bezpośrednie przechowywanie bardzo dużych wartości pól. Gdy próbuje się przechowywać wiersz, który przekracza ten rozmiar, TOAST dzieli dane dużych kolumn na mniejsze „kawałki” i przechowuje je w tabeli TOAST. Każda tworzona tabela ma swoją powiązaną (unikalną) tabelę TOAST, która może lub nie być używana, w zależności od rozmiaru wstawianych wierszy. Wszystko to jest przezroczyste dla użytkownika i jest domyślnie włączone. Mechanizm ten polega na podzieleniu dużego wpisu kolumny na 2 kB bajty i przechowywaniu ich jako fragmenty w tabelach TOAST. Następnie przechowuje długość i wskaźnik do wpisu TOAST tam, gdzie normalnie przechowywana jest kolumna. Ze względu na sposób implementacji systemu wskaźników większość typów kolumn obsługiwanych przez TOAST ma maksymalny rozmiar 1 GB.
TOAST ma wiele zalet w porównaniu do bardziej prostego podejścia, takiego jak umożliwienie wartości wiersza na rozciąganie się na wiele stron. Duże wartości atrybutów TOAST są wyciągane (jeśli w ogóle są wybierane) w momencie wysyłania zestawu wyników do klienta. Samą tabelę będzie znacznie mniejsza, a większość jej wierszy zmieści się w współdzielonym buforze podręcznym, niż miałoby to miejsce bez żadnego przechowywania (TOAST) poza linią. Istnieje również większe prawdopodobieństwo, że zestawy sortowań staną się mniejsze, co oznacza, że sortowania zostaną wykonane całkowicie w pamięci.
Mapa wolnego miejsca – Free Space Map
Każda tabela ma mapę wolnego miejsca, która przechowuje informacje o dostępnym wolnym miejscu w tabeli. Mapa wolnego miejsca jest przechowywana w pliku o nazwie z numerem filenode plus sufiksem _fsm.
Wartości przechowywane w mapie wolnego miejsca nie są dokładne. Są zaokrąglone do precyzji 1/256 rozmiaru strony (32 bajty dla domyślnych 8 kB) i nie są aktualizowane w pełni w miarę wstawiania i aktualizowania krotek. Niektóre operacje aktualizują mapę wolnego miejsca, takie jak usuwanie wszystkich wierszy, ale operacja VACUUM aktualizuje mapę wolnego miejsca dla przyszłych wierszy, aby móc określić, na której stronie mogą się one zmieścić.
VACUUM
Mapa wolnego miejsca jest aktualizowana przez wykonanie VACUUM, ponieważ UPDATE lub DELETE wiersza nie usuwa natychmiast starej wersji wiersza. To podejście jest konieczne, aby uzyskać korzyści z wielowariantowej kontroli współbieżności (MVCC): wersja wiersza nie może być usuwana, gdy jest wciąż potencjalnie widoczna dla innych transakcji. Jednak w końcu przestarzała lub usunięta wersja wiersza nie jest już interesująca dla żadnej transakcji. Zajmowane przez nią miejsce musi zostać odzyskane i ponownie wykorzystane przez nowe wiersze, aby uniknąć nieograniczonego wzrostu wymagań dotyczących miejsca na dysku.
Standardowa forma VACUUM usuwa martwe wersje wierszy z tabeli i oznacza przestrzeń dostępną do przyszłego ponownego użycia. Jednak nie zwraca przestrzeni systemowi operacyjnemu, z wyjątkiem specjalnego przypadku, gdy jedna lub więcej stron na końcu tabeli staje się całkowicie wolna i można uzyskać wyłączne blokowanie tabeli. To nie oznacza, że wolne miejsce wewnątrz strony jest fragmentowane. VACUUM zapisuje cały blok, efektywnie upakowując pozostałe wiersze i pozostawiając pojedynczy spójny blok wolnego miejsca na stronie.
VACUUM FULL
W przeciwieństwie do tego, VACUUM FULL aktywnie kompresuje tabele, zapisując całkowicie nową wersję pliku tabeli bez martwego miejsca. Minimalizuje to rozmiar tabeli, ale może to potrwać długo. Wymaga również dodatkowej przestrzeni dyskowej dla nowej kopii tabeli, do czasu zakończenia operacji. Celem rutynowego VACUUM jest unikanie konieczności użycia VACUUM FULL. Idea polega na utrzymaniu stabilnego użycia miejsca na dysku: każda tabela zajmuje miejsce równoważne jej minimalnemu rozmiarowi plus miejsce zużywane między wykonywaniem operacji VACUUM.
W przeszłości, gdy VACUUM był wykonywany, musiał przejrzeć każdy wiersz w tabeli, ponieważ nie było informacji o tym, które strony mogą nie zostać zaktualizowane od ostatniego VACUUM. PostgreSQL wprowadził mapę widoczności, dzięki czemu VACUUM może teraz wykonywać częściowe skanowanie danych tabeli, pomijając strony oznaczone jako w pełni widoczne. Częściowe skanowanie oznacza mniejszą liczbę operacji I/O dla VACUUM. Struktura PostgreSQL w przypadku regularnego optymalizowania, odwdzięcza się świetną wydajnością! Warto dodatkowo poznać kluczowe parametry poprawiające wydajność PostgreSQL.
Mapa widoczności – Visibility Map
Każda tabela ma również mapę widoczności (VM), która śledzi, które strony zawierają tylko krotki, które są widoczne dla wszystkich aktywnych transakcji. Innymi słowy, śledzi, które strony są znane z braku martwych wierszy. Mapa widoczności jest przechowywana obok pliku tabeli w osobnym pliku, nazwanym na podstawie numeru filenode relacji, z dodatkowym sufiksem _vm. Na przykład, jeśli numer filenode dla tabeli to 27741, mapa widoczności jest przechowywana w pliku o nazwie 27741_vm, w tym samym katalogu co główny plik relacji.
W poprzednim rozdziale widzieliśmy, że martwe wiersze wynikają z mechanizmu MVCC.
Mapa widoczności przechowuje po prostu jeden bit na stronę heapa. Ustawiony bit oznacza, że wszystkie krotki na stronie są widoczne dla wszystkich transakcji. Oznacza to, że strona nie zawiera żadnych krotek, które muszą zostać usunięte przez proces VACUUM. Bity mapy widoczności są ustawiane tylko przez operację VACUUM, ale są usuwane przez każdą operację modyfikującą dane na stronie.
Jak widzisz struktura PostgreSQL wcale nie jest taka straszna, ta pigułka wiedzy pozwoli Ci opanować podstawy PostgreSQL dla administratora!
Zajrzyj też do dokumentacji PostgreSQL Database Physical Storage!