Chciałbym przybliżyć Ci dwa z kluczowych mechanizmów w Oracle Database mających wpływ na wydajność – row chaining i row migration. Na początek przeanalizujmy strukturę bloku Oracle. Wszystkie tabele i indeksy składają się z bloków, które (domyślnie) mają ten sam rozmiar w danej bazie danych. Rozmiar jest określany już na etapie tworzenia bazy danych. Bloki mają zazwyczaj rozmiar 8K (domyślny), rzadziej 16K, a jeszcze rzadziej mogą mieć rozmiar 2K, 4K lub 32K.
Jeśli chcesz używać rozmiaru bloku innych niż 8K lub 16K, musisz mieć bardzo dobry powód przed dokonaniem takiej zmiany. Możesz tworzyć przestrzenie tabel(Oracle tablespace) z innym rozmiarem bloku, ale robi się to tylko gdy wyraźnie jest taka potrzeba. Wielkość bloku powinna być zawsze dobierana do typu zapytań wykonywanych na bazie. Dla tego elementu konfiguracji domyślne ustawienia w większości przypadków są tymi właściwymi 🙂

Budowa i wielkość bloku danych
Na „górze” bloku znajduje się nagłówek bloku, który zawiera informacje i struktury kontroli dostępu do wierszy w bloku. Wiersze są w rzeczywistości wstawiane od „dołu” bloku w górę, aż do momentu, gdy zostanie dostępne tylko miejsce PCTFREE. Jest to wolne miejsce pozostawione na aktualizacje wierszy i domyślnie wynosi 10%.
Dlaczego używać rozmiaru bloku 16K zamiast domyślnych 8K? Zazwyczaj używa się go w bazach danych Data Warehouse lub innych bazach danych przechowujących długie wiersze. W większości takich przypadków będziesz marnować mniej miejsca w blokach i unikniesz łączenia wierszy(o której przeczytasz w kolejnym akapicie) dzięki większym blokom. Jeśli masz krótkie wiersze i bazę typu OLTP (gdzie czytasz wiele pojedynczych wierszy), to z kolei blok 16K nie jest optymalny dla pamięci buffer cache w SGA. Popsuje to efektywność wykorzystania pamięci i samą wydajność. Tutaj sprawdzi się lepiej 8K.
Dobranie odpowiedniej wielkości bloków polega na wyważeniu jego wielkości, tak aby nie degradować wydajności bazy. Degradacja ta powodowana może być między innymi właśnie przez row migration i row chaining.
Aktualizacja wiersza
Czasami aktualizacja wiersza wydłuża go. Wiersze są upakowane jeden po drugim, więc można zrobić jedną z dwóch rzeczy:
- Jeśli jest wystarczająco dużo miejsca na „górze” bloku, wiersz jest po prostu przenoszony tam, a wskaźniki w nagłówku są aktualizowane.
- Jeśli nie ma wystarczająco dużo miejsca na „górze” bloku, ale jest w całym bloku, wiersz jest przenoszony na górę. Pozostałe bloki zostają przetasowane.
Jednak jeśli zaktualizujesz wiersz i nie ma wystarczająco dużo wolnego miejsca w bloku, co robi Oracle? Przenosi wiersz. Pozostawia nagłówek wiersza na oryginalnym miejscu, który zawiera wskaźnik (ROWID) do nowego położenia wiersza. Miejsce to może znajdować się w bloku bardzo odległym od oryginalnego wiersza, nawet w innym pliku przestrzeni tabeli. Wszystkie kolumny wiersza są przenoszone do nowego położenia. Ponieważ zmieniasz dwa bloki, generuje się jeszcze więcej operacji REDO!
Row migration
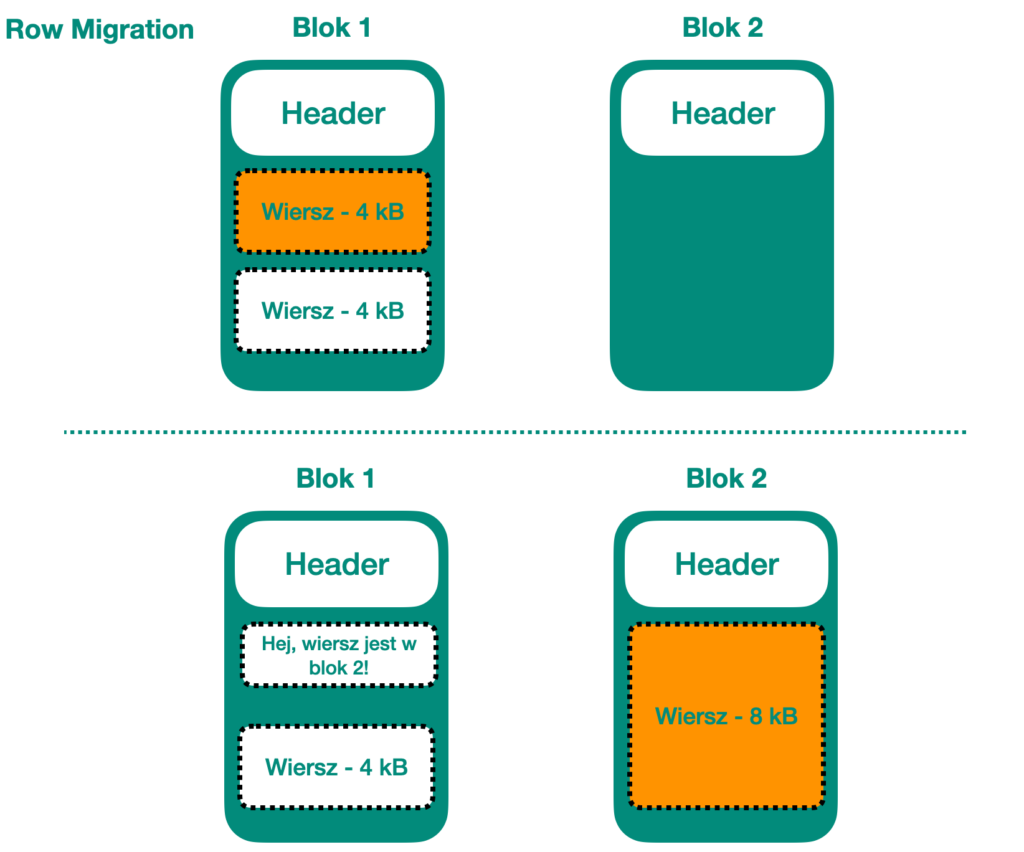
Dlaczego Oracle pozostawia nagłówek na miejscu i po prostu wskazuje nowe położenie wiersza? Otóż, jeśli ROWID dla wiersza ulegnie zmianie (jak by to miało miejsce, gdy zmieniłby się blok, w którym się znajduje), to wszystkie indeksy odwołujące się do tej kolumny musiałyby być zmienione. Dodatkowo, wszelkie wewnętrzne odwołania ROWID wewnątrz Oracle musiałyby być zarządzane. To dodatkowa praca dla bazy danych. Zazwyczaj ludzie chcą, aby aktualizacje odbywały się jak najszybciej.
Skutkiem tego jest to, że jeśli wybierasz ten wiersz za pomocą na przykład indeksu, Oracle znajdzie nagłówek wiersza i będzie musiał wykonać drugie odczytanie jednego bloku, aby uzyskać rzeczywisty wiersz. To więcej operowania na danych wejścia-wyjścia i dwa bloki w pamięci podręcznej bufora, a nie jeden. Jest to więc wolniejsze. Duża liczba row migration może znacznie spowolnić zakresy skanów indeksów.
Wpływ na skanowanie pełnej tabeli w przypadku prostego przeniesionego wiersza jest praktycznie zerowy. Oracle przeszukuje tabele(segment Oracle), a rzeczywisty wiersz zostanie znaleziony niezależnie od tego, gdzie znajduje się w tabeli (lub partycji). Nagłówek jest po prostu odrzucany.
Praktyczne ćwiczenia z konfiguracji Oracle Database znajdziesz w kursie: Praktyczna Administracja – Oracle Database!
Row chaining
Łańcuchowanie wierszy występuje, gdy wiersz jest zbyt szeroki, aby zmieścił się w jednym bloku. W takim przypadku Oracle nie ma innego wyboru, jak podzielić wiersz na częśći. W rzeczywistości każdy wiersz składa się z nagłówka i części wiersza, ale istnieje tylko jeden nagłówek. Część wiersza z danymi jest przenoszona podczas migracji wierszy. Jeśli wiersz jest większy niż blok, to nagłówek wiersza i pierwsza część są umieszczane w pierwszym dostępnym bloku. Jeśli tworzony jest duży wiersz, następne części są zazwyczaj umieszczane w kolejnych blokach.
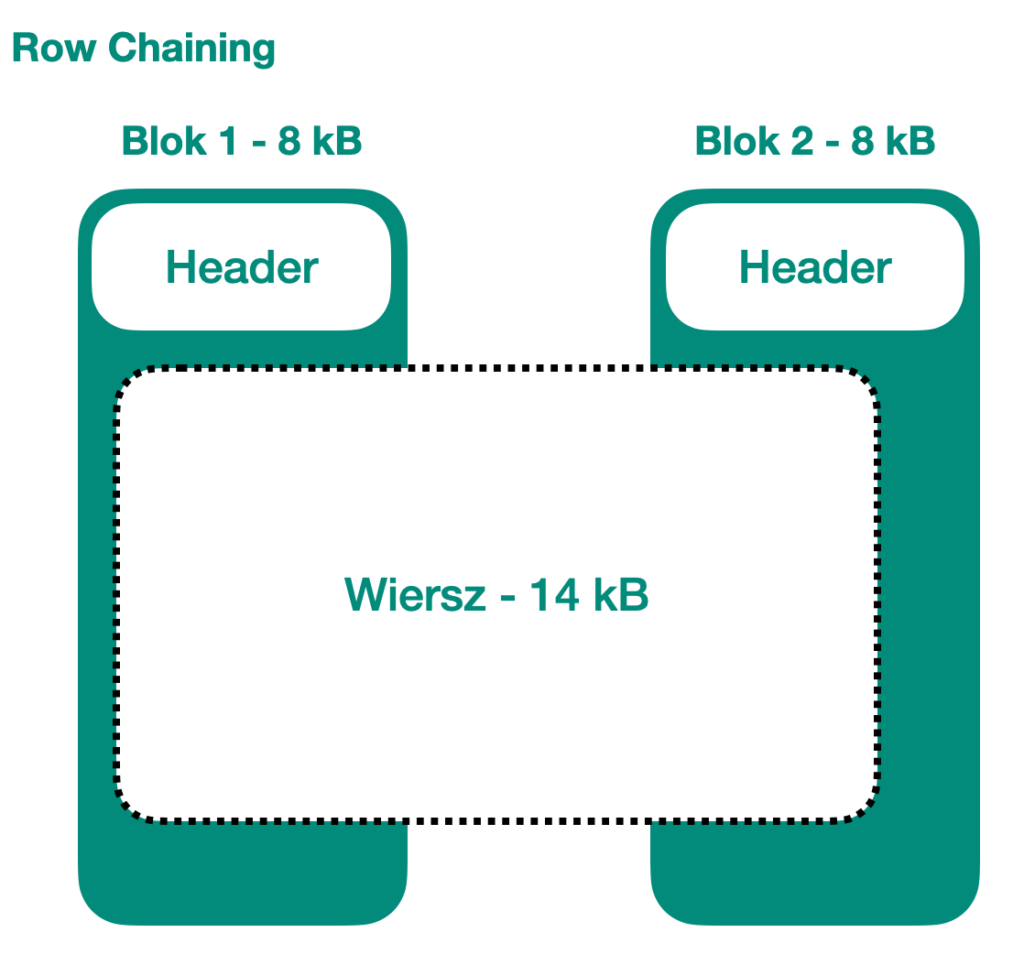
Oczywiście, wiersz może być ogromny i rozciągać się na wiele, wiele bloków. Jest to zazwyczaj oznaką, że projekt tabeli i fizyczna implementacja bazy danych nie zostały wystarczająco przemyślane. Powinieneś pogadać na ten temat z programistami. Kilka małych zmian może znacznie zwiększyć wydajność!
Łatwo można zauważyć, że jeśli odczytujesz pojedynczy wiersz, na przykład poprzez wyszukiwanie indeksowe, Oracle odczytuje tyle bloków, ile obejmuje wiersz. To więcej operacji wejścia-wyjścia. Jednak nie będzie to konieczne, jeśli wszystkie kolumny, których potrzebujesz, znajdują się w pierwszej części wiersza . Oracle zatrzyma przeglądanie kolejnych części wiersza, gdy już zdobędzie wszystkie potrzebne kolumny.
Tego rodzaju łańcuchowanie wierszy, gdzie części wiersza znajdują się w sąsiadujących blokach, nie stanowi większego problemu podczas pełnego skanowania tabeli.
Jeśli zaktualizowałeś wiersz tak, że jest za duży dla bloku, twój wiersz może być zarówno łańcuchowany, jak i migrowany. Części wiersza mogą być niesąsiednie, zwłaszcza jeśli aktualizowałeś wiersz za pomocą kilku instrukcji/w określonym okresie czasu.