PostgreSQL to prawdopodobnie najbardziej zaawansowana baza danych na rynku otwartych, relacyjnych baz danych. Wydana po raz pierwszy w 1989 roku, od tego czasu przeszła wiele udoskonaleń. Jeśli powoływać się na najnowsze statystyki, jest czwartą najpopularniejszą bazą danych. W tym wpisie pokaże Ci jak wygląda architektura PostgreSQL, oraz w jaki sposób poszczególne komponenty współpracują ze sobą. Wpis z serii PostgreSQL dla początkujących.

Architektura PostgreSQL – schemat
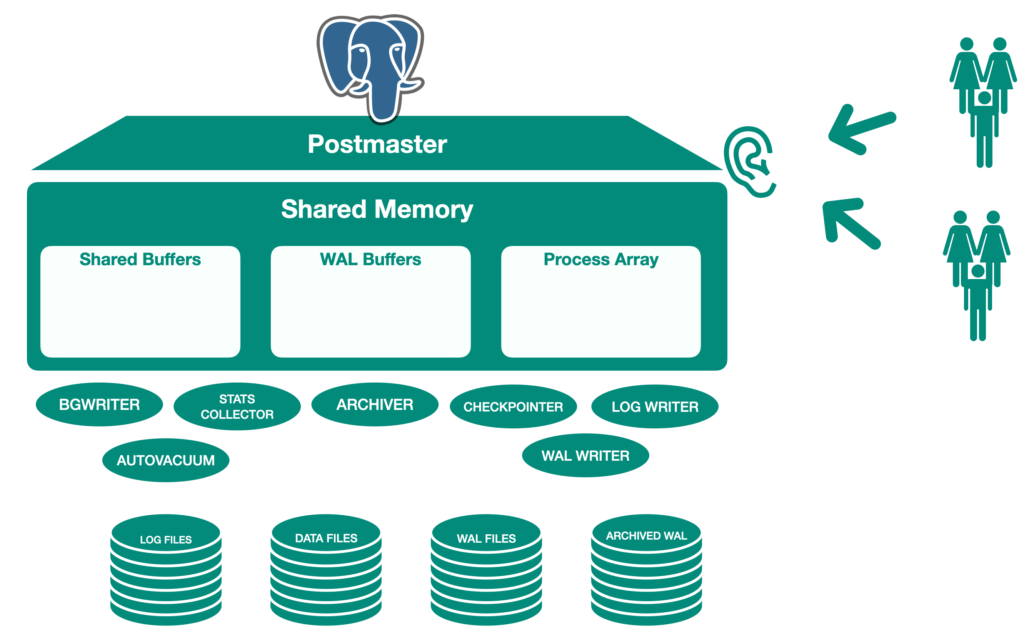
Pamięć współdzielona – Shared Memory
Pamięć współdzielona odnosi się do pamięci zarezerwowanej na buforowanie bazy danych oraz buforowanie dziennika transakcji. Najważniejszymi elementami w pamięci współdzielonej są Bufor Współdzielony oraz bufory WAL (Write Ahead Log).
Bufor Współdzielony – Shared Buffer
Celem Bufora Współdzielonego jest minimalizowanie operacji odczytu/zapisu na dysku. W tym celu muszą zostać spełnione następujące zasady:
- Trzeba szybko uzyskiwać dostęp do bardzo dużych buforów (dziesiątki, setki gigabajtów).
- Należy minimalizować rywalizację, gdy wielu użytkowników jednocześnie uzyskuje do niego dostęp.
- Często używane bloki muszą pozostawać w buforze jak najdłużej.
Bufor WAL
Bufor WAL to bufor tymczasowo przechowujący zmiany w bazie danych. Zmiany te są zapisywane do pliku WAL w określonym momencie. Z perspektywy tworzenia kopii zapasowych i przywracania, bufory WAL oraz pliki WAL są bardzo ważne.
Typy procesów PostgreSQL w architekturze PostgreSQL
PostgreSQL posiada cztery typy procesów.
- postmaster (Demon)
- background
- backendu
- klienta
Proces postmaster
Proces postmaster jest pierwszym procesem uruchamianym podczas uruchamiania PostgreSQL. Podczas uruchamiania przeprowadza proces odtwarzania, inicjalizuje pamięć współdzieloną i uruchamia procesy background. Tworzy również proces backendu w przypadku żądania połączenia od procesu klienta.
Jeśli sprawdzisz relacje między procesami za pomocą polecenia pstree, zobaczysz, że proces postmaster jest rodzicem wszystkich procesów.
Procesy background
| Proces | Rola |
|---|---|
| logger | Zapisuje komunikaty błędów do plików log. |
| checkpointer | Kiedy wykonywany jest checkpoint, proces ten zapisuje brudne bloki do plików danych. |
| writer | Zapisuje brudne bloki do plików danych. |
| wal writer | Zapisuje bufor WAL do plików WAL. |
| Autovacuum launcher | Powołuje procesy Autovacuum PostgreSQL który przeprowadzają proces VACUUM na tabelach kwalifikujących się do niego. |
| archiver | Kiedy baza jest w trybie archive, robi kopie każdego pliku WAL do lokalizacji zapasowej. |
| stats collector | Zbiera statystyki na temat sesji i użycia tabel w bazie. |
Proces backend
Maksymalna liczba procesów backenowych jest ustawiana przez parametr max_connections, a wartość domyślna wynosi 100. Kiedy proces backendu wykonuje zapytanie użytkownika i przekazuje wyniki, wymagane są pewne struktury pamięci do wykonania zapytania, nazywane pamięcią lokalną. Główne parametry związane z pamięcią lokalną to:
- work_mem – przestrzeń używana do sortowania, operacji bitmapowych, połączeń typu hash i połączeń typu merge. Wartość domyślna to 4 MB.
- maintenance_work_mem – przestrzeń używana do operacji Vacuum i CREATE INDEX. Wartość domyślna to 64 MB.
- temp_buffers – przestrzeń używana do tymczasowych tabel. Wartość domyślna to 8 MB.
Każdy z nich ma kluczowe znaczenie jeżeli chodzi o wydajność PostgreSQL.
Proces klienta
Proces klienta odnosi się do procesu w tle, który jest przypisany do każdego połączenia użytkownika z backendem. Jeśli proces postmaster wydziela proces potomny, jest on dedykowany obsłudze danego połączenia użytkownika.
Jeżeli chcesz kompleksowo poznać administrację bazą danych PostgreSQL sprawdź: Kurs Praktyczna Administracja PostgreSQL!
Architektura bazy danych
Oto kilka istotnych rzeczy do zapamiętania na temat samych baz, które architektura PostgreSQL także obejmuje.
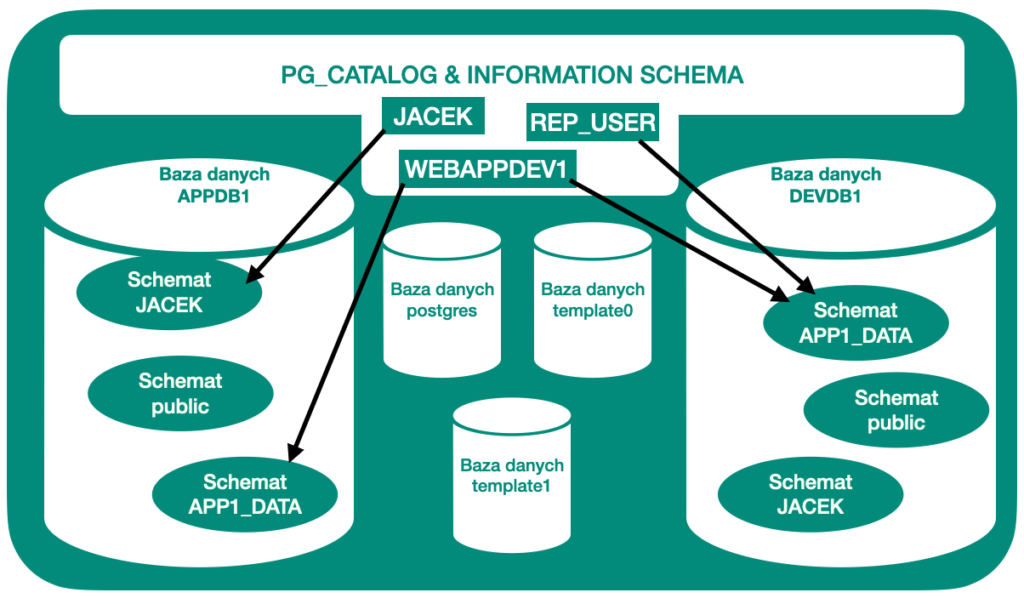
Elementy związane z bazą danych
- PostgreSQL składa się z kilku baz danych. Nazywamy to klastrem bazy danych.
- Dane i struktura fizycznie przetrzymywane są w tzw. PGDATA.
- Podczas wykonywania initdb() tworzone są bazy danych template0, template1 i postgres.
- Bazy danych template0 i template1 są szablonami do tworzenia baz danych użytkownika i zawierają tabele katalogowe systemu.
- Lista tabel w bazach template0 i template1 jest taka sama bezpośrednio po wykonaniu initdb(). Jednak w bazie template1 można tworzyć obiekty, których potrzebuje użytkownik.
- Inicjalizacja nowej bazy danych użytkownika jest tworzona przez sklonowanie template1.
Elementy związane z przestrzenią tabel:
- Przestrzenie tabel pg_default i pg_global są tworzone bezpośrednio po initdb().
- Jeśli nie określisz przestrzeni dla tabeli podczas jej tworzenia, będzie ona przechowywana w przestrzeni pg_default.
- Tabele zarządzane na poziomie klastra bazy danych są przechowywane w przestrzeni pg_global.
- Fizyczne położenie przestrzeni tabel pg_default to $PGDATA/base.
- Fizyczne położenie przestrzeni tabel pg_global to $PGDATA/global.
- Jedna przestrzeń tabel może być używana przez wiele baz danych. W tym przypadku tworzony jest podkatalog specyficzny dla bazy danych w katalogu przestrzeni tabel.
- Tworzenie przestrzeni tabeli użytkownika tworzy dowiązanie symboliczne do przestrzeni tabeli użytkownika w katalogu $PGDATA/tblspc.
Elementy związane z tabelą:
- Na jedną tabelę przypada trzy pliki.
- Pierwszy do przechowywania danych tabeli. Nazwa pliku to OID tabeli.
- Drugi do zarządzania wolnym miejscem w tabeli. Nazwa pliku to OID_fsm.
- Trzeci do zarządzania widocznością bloku tabeli. Nazwa pliku to OID_vm.
- Indeks nie posiada pliku _vm. Oznacza to, że ma tylko pliki OID i OID_fsm.
Inne rzeczy do zapamiętania…
Nazwa pliku podczas tworzenia tabeli i indeksu to OID, a na tym etapie OID i pg_class.relfilenode są sobie równe. Jednak gdy wykonuje się operację przepisywania (Truncate, CLUSTER, Vacuum Full, REINDEX itp.), wartość relfilenode dotkniętego obiektu jest zmieniana, a nazwa pliku również jest zmieniana na wartość relfilenode. Można łatwo sprawdzić położenie i nazwę pliku, używając pg_relation_filepath (‘< object name >‘).
Sprawdź artykuł na temat struktury PostgreSQL!